
Designed for AI inference! NVIDIA retains a trump card, Rubin CPX GPU, may it change the ASIC competition landscape?

As generative AI applications flourish, AI inference has become the next main battlefield. Compared with AI training, inference is closer to terminal applications and directly determines whether AI technology can be implemented and bring actual value.
In fact, AI guru Andrew Ng said in an earlier interview with the media in 2023, "I hope that in the future, inference will occur more often than training, so that AI will succeed." This means that the success of AI technology is related to the prosperity of inference applications, and a large part of AI monetization scenarios fall in the inference market.
On the other hand, a large language model may take weeks to months to train. Once completed, it can be used countless times around the world to generate text, answer questions, or translate languages through the cloud or terminal devices. Therefore, the demand and breadth of application of inference often far exceeds that of training.
NVIDIA launches Rubin CPX GPU, designed for “long-situation” AI inferenceFaced with the huge business opportunities in the inference market, NVIDIA announced the launch of Rubin CPX GPU, a new generation of GPU specially designed for large-scale situational inference. It will work with Rubin GPU and Vera CPU to accelerate specific workloads. It is expected to be launched by the end of 2026.

NVIDIA points out that NVIDIA Rubin CPX can provide the highest performance and token gains when processing long situations, far beyond what today's system designs can handle. This transforms AI Code Assistant from a simple code generation tool into a complex system that can understand and optimize large software projects.
Generally speaking, an AI model may need to use up to 1 million tokens to process a one-hour video, which has reached the limit of traditional GPU computing. Rubin CPX integrates video decoders and encoders, as well as long-term context inference processing technology into a single chip for long-format applications such as video search and high-quality video generation. In addition, Rubin CPX GPUs feature powerful NVFP4 computing resources in an affordable single-chip design and are optimized to deliver extremely high performance and energy efficiency for AI inference tasks.
Next, this article will share several highlights based on market news.
Highlight 1: CPX GPU uses GDDR7 instead of HBM memoryCurrently, the inference of large-scale AI models is usually divided into two stages, namely the “Context Phase” (Prefill) and the “Generation Phase” (Decode). The former is a computationally intensive initial stage, used to process the input and generate the first output token; the latter is where the model generates subsequent tokens based on the processed context.
To put it simply, the context stage can be imagined as the initial stage of "reading comprehension", which requires a lot of calculations because the model needs to process all the information, build a brain memory bank, understand the meaning, and be ready to answer questions or generate content; the generation stage is the "start answering" stage. The model uses the context memory established in the first stage to generate one word, word or sentence at a time. The generation stage mainly relies on the access speed of the memory, because the model needs to quickly find the understood information to generate subsequent text.
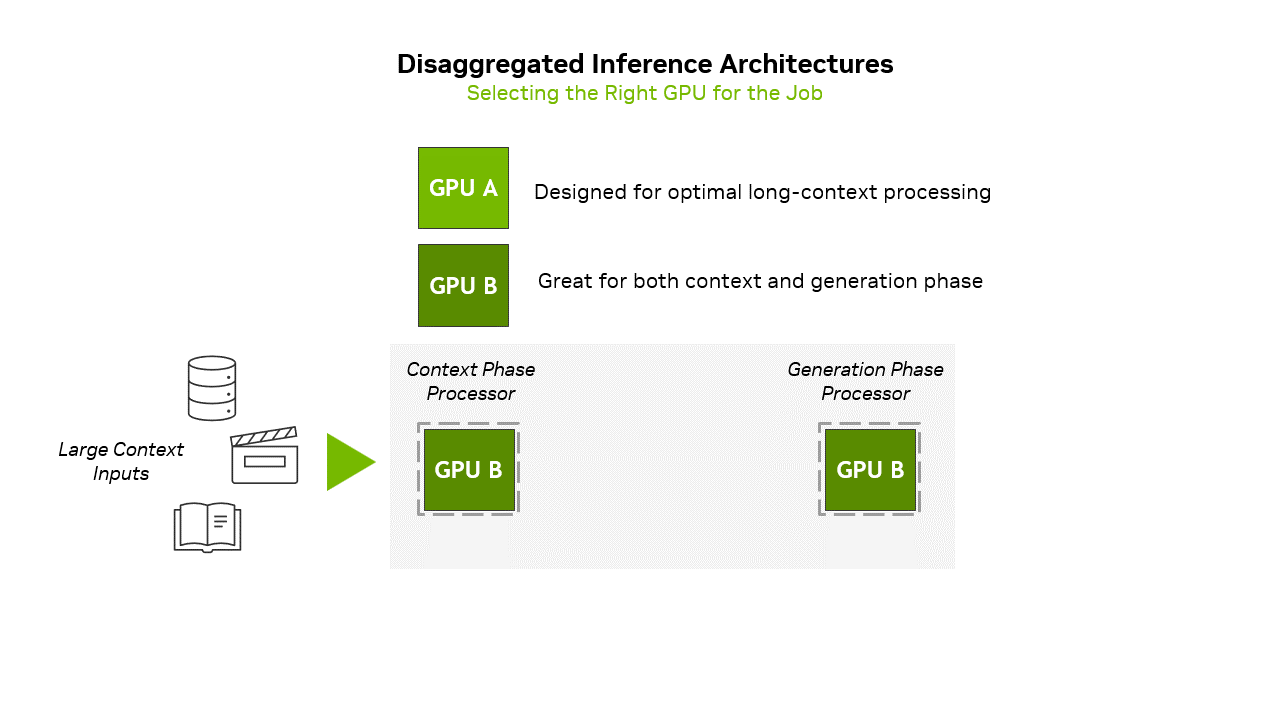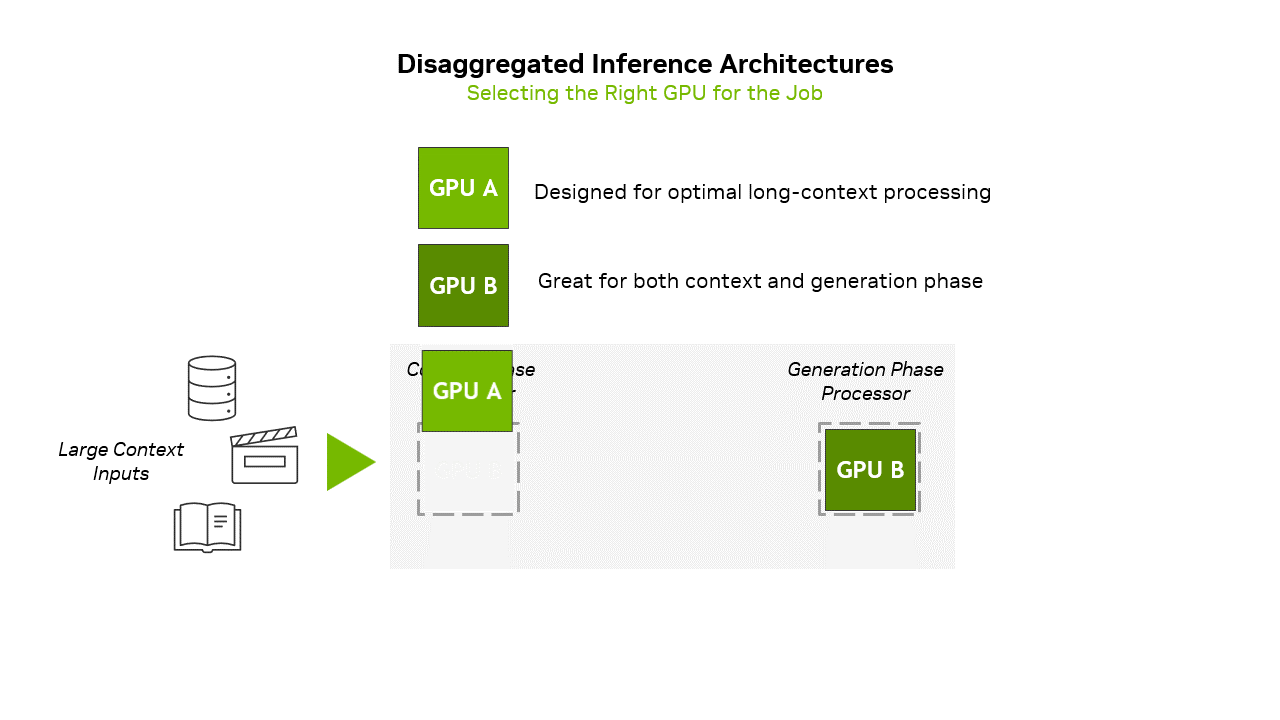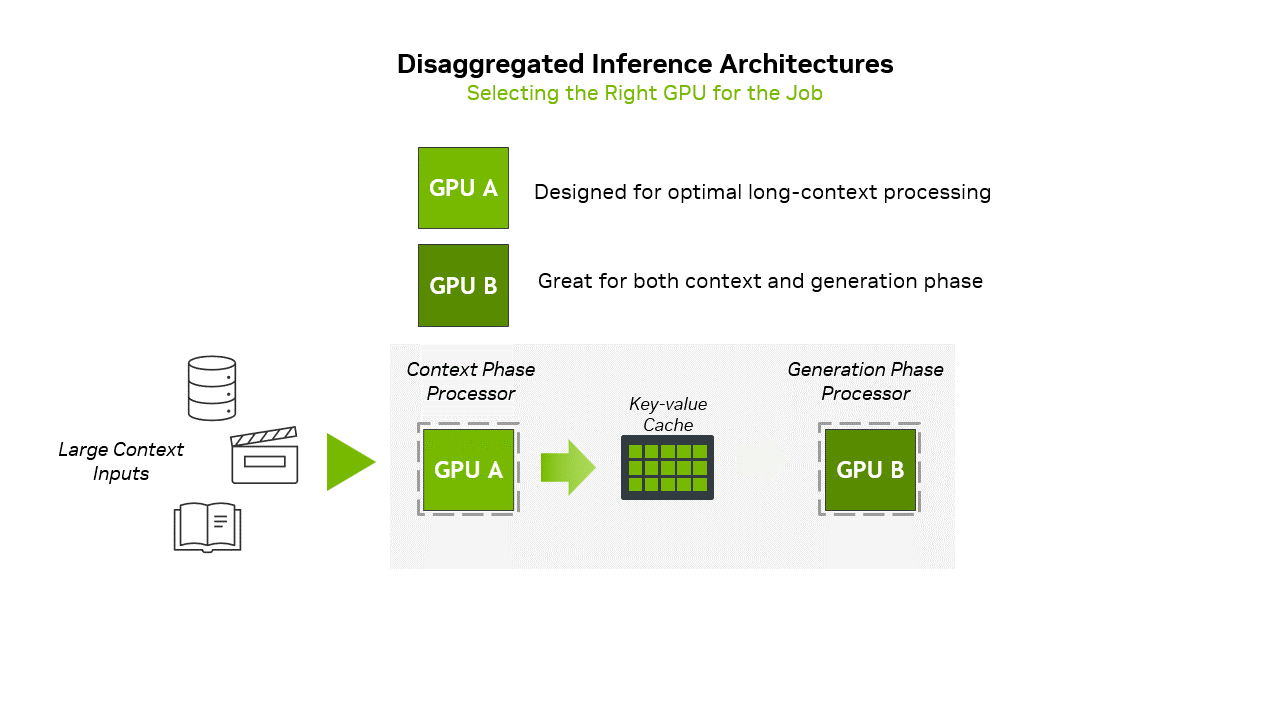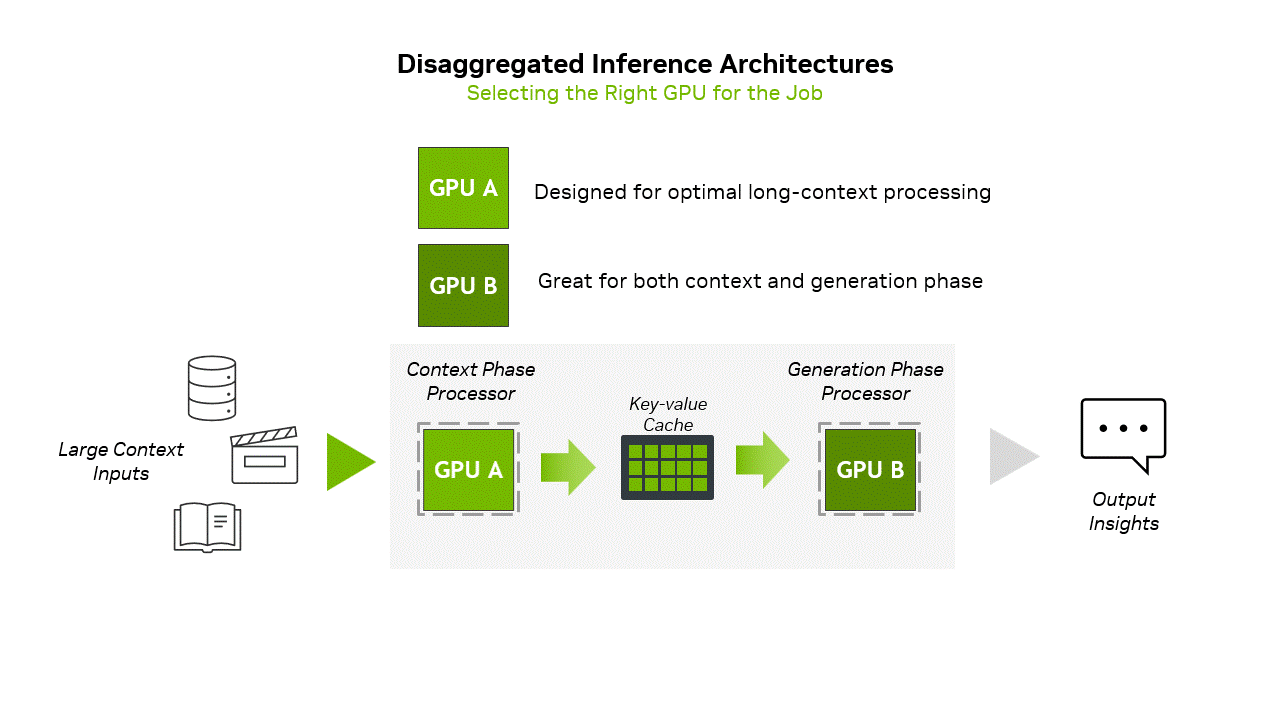
▲ NVIDIA adopts a separated inference architecture to align the workloads of the context phase and the generation phase through GPU capabilities. (Source: NVIDIA)
NVIDIA’s Rubin CPX GPU is mainly designed for long context inference, which requires extremely high computational throughput to handle context workloads of more than one million tokens. Therefore, sufficient memory is required, but the bandwidth is not necessarily high. Although traditional data center GPUs have a large amount of HBM memory and can handle this type of workload, they are not efficient in this task.
So the first highlight is the use of 128 GB of GDDR7 memory instead of the HBM memory commonly used in the past, which makes this GPU more affordable and accelerates the most demanding context-based workloads.
As for the second stage, it is mainly limited by memory bandwidth and interconnection, and requires fast access to previously generated tokens and attention caches. Therefore, traditional data center GPUs, such as Blackwell Ultra or Rubin GPU's HBM4 memory, can be used to efficiently handle such tasks.
Although the bandwidth of GDDR7 is much lower than that of HBM3E or HBM4, the power consumption is lower, the cost per GB is significantly reduced, and the expensive CoWoS advanced packaging technology is not required. Therefore, the Rubin CPX GPU is not only cheaper than the general Rubin processor, but also the power consumption is greatly reduced, making the heat dissipation design simpler. NVIDIA also stated that every US$100 million invested in Rubin CPX can bring up to US$5 billion in word income, which is equivalent to a return on investment of 30 to 50 times. It is a very attractive solution for customers..
Highlight 2: Rubin CPX does not have NVLink, but provides a high degree of expansionNVIDIA pointed out that Rubin CPX offers a variety of configuration options, including Vera Rubin NVL144 CPX, which can be combined with the NVIDIA Quantum-X800 InfiniBand scale-out computing architecture, or integrated with the Spectrum-X Ethernet platform using Spectrum-XGS Ethernet technology and ConnectX-9 SuperNIC.

▲ NVIDIA Vera Rubin NVL144 CPX rack and cabinet, equipped with Rubin Context GPU (Rubin CPX), Rubin GPU, and Vera CPU. (Source: NVIDIA)
In order to support the performance of Rubin CPX, NVIDIA simultaneously launched the PCIe Switch+CX8 I/O board, which is the world's first mass-produced PCIe 6.0 specification I/O product. It integrates the PCIe Switch chip and ConnectX-8 SuperNIC on the same large board, equipped with 9 PCIe slots and 8 NIC connectors.
By combining the two key components of PCIe Switch and CX8 NIC into one, this board is like the "nerve center" of the AI server, integrating multiple important chips together, simplifying the server design and the number of parts, allowing all components to communicate with each other at ultra-high speed.
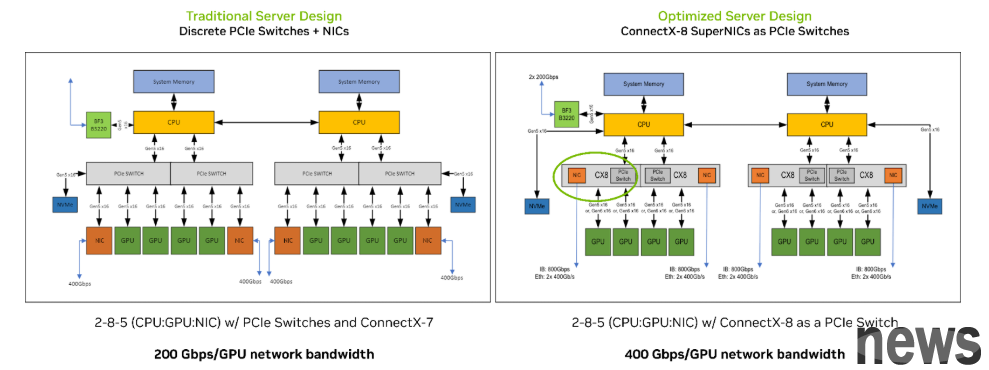
▲ Comparison of traditional server design (left) and optimized server design (right) using ConnectX-8 SuperNIC. (Source: NVIDIA)
Compared with NVLink, which pursues extremely high point-to-point bandwidth in training scenarios, inference scenarios place more emphasis on flexible resource allocation and shared computing power in a single machine or multiple GPU servers. Through PCIe Switch, data centers can more effectively manage GPU computing resources to cope with inference requests from different applications and different models.
Highlight Three: Highly Integrated Software and HardwareIn terms of software, Rubin CPX fully supports NVIDIA’s AI ecosystem, including CUDA and the Dynamo platform that can improve efficiency, Nemotron models, and the NVIDIA AI Enterprise suite.
In addition, developers of AI models and products do not need to manually split the "context phase" and "generation phase" of inference between GPUs to run on the Rubin NVL144 CPX rack-scale solution. NVIDIA recommends using its Dynamo software orchestration layer to intelligently manage and distribute inference workloads across different types of GPUs. NVIDIA notes that Dynamo can also manage KV cache transfers to minimize latency.
These software tools allow enterprises to easily deploy AI applications whether in the cloud, data center, or workstation. Coupled with NVIDIA's vast developer community and more than 6,000 applications, Rubin CPX's hardware advantages can be quickly transformed into actual business value.
NVIDIA CEO Jensen Huang said that the Vera Rubin platform will mark another leap forward in the field of AI computing, not only launching a new generation of Rubin GPUs, but also creating a new processor category called "CPX". Rubin CPX is the first CUDA GPU purpose-built for large-scale contextual AI, enabling models to handle inference tasks with millions of tokens simultaneously.
What does the market think of Rubin CPX GPUs?Judging from the industry's reaction, it remains to be seen whether this chip can eat into the niche market that ASICs should enter. Because the use of GDDR7 memory has obvious cost advantages, coupled with the solid integration of software and hardware, it is one of the very attractive options for the industry.
Since Rubin CPX is classified as a dedicated GPU, there may be a lot of pressure on Broadcom and AMD. Industry insiders pointed out that many major customers are still looking for alternatives to NVIDIA, mainly due to cost considerations. It remains to be seen whether the launch of Rubin CPX will be attractive, but for customers who want to avoid actively using NVIDIA solutions, they may still continue the original route.



